DataStructure Test
pnucse2019-1ldhDataStructure
PNU CSE 2019 2nd Semester DataStructure Class
temp..
Programming Assignment#2
정렬 알고리즘 비교
이번 과제는 주어진 수열을 정렬하는 알고리즘을 비교분석하는 것이다. 이 때 사 용할 알고리즘을 다음과 같다. 삽입정렬(insertion), 버블정렬(bubble), 선택정렬 (selection), 퀵정렬(quick), 합병정렬(merge), 힙정렬(heap), 기수정렬(radix)이다. 일반적으로 시간을 측정할 때는 clock()함수를 사용한다. 각 알고리즘은 함수로 나 타내고 함수를 호출할 때 시간을 측정하고 함수가 끝난 뒤에 측정시간을 종료한다.
gen_list.cpp
listXXX(XXX는 개수) 파일 생성을 구현. rand()의 특성상, 단순히 rand()%N; 으로는 32767의 최대값만 나타나기 때문에 다음과 같이 bit 이동연산을 이용하여 0 ~ 99999 까지의 수를 랜덤 할당 함.
(int)(((double)((rand()<<15) | rand())) / (((RAND_MAX<<15) | RAND_MAX) + 1) * (100000))
comp_sort.cpp
삽입정렬(insertion), 버블정렬(bubble), 선택정렬 (selection), 퀵정렬(quick), 합병정렬(merge), 힙정렬(heap), 기수정렬(radix)이 각각 구현되어 있음. gen_list.cpp를 통해 생성된 listXXX 파일을 입력하면, 각각의 정렬 연산의 시간을 계산하여 resultXXX.txt 파일로 출력함.
sortgraph.py
알고리즘 각각의 연산 시간이 저장된 resultXXX.txt을 파싱하여 연산시간을 그래프로 표현해 줌.
연산 환경
C++은 gcc로 compile 하였다.
Sorting Algorithm 연산 결과
- 10개 부터 1000개의 경우
위와 같은 연산환경에서는 10000개의 정렬 연산이 되기 전 까지는 0.00x초 미만 대의 연산 결과가 일어나기 때문에, 1초(Second) 관점에서의 여러 종류 Sorting Algorithm간에 큰 차이가 없다고 할 수 있다.
- 10000개의 경우
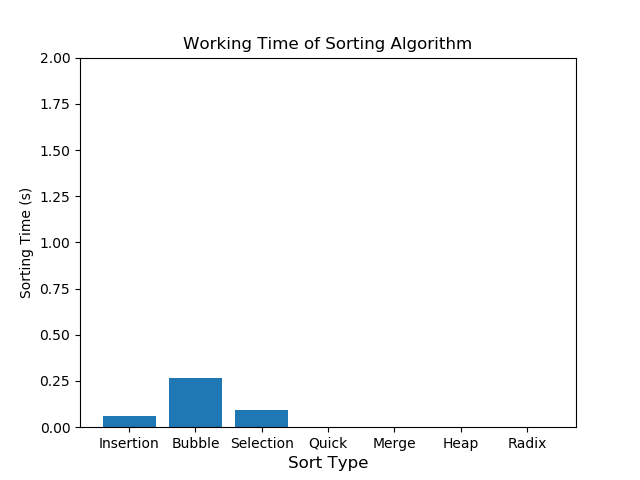
10000개의 연산 부터는 Sorting Algorithm간에 속도 차이가 드러난다.
삽입정렬 0.06초, 버블정렬 0.268초 선택정렬이 0.095초가 소모되었다.
- 100000개의 경우
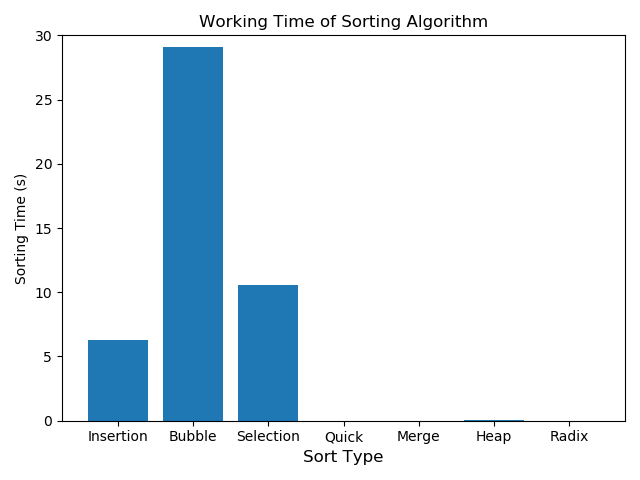
100000개의 연산의 경우 Sorting Algorithm간 처리 속도가 현저히 차이가 난다.
Sorting Algorithm Time-Complexity
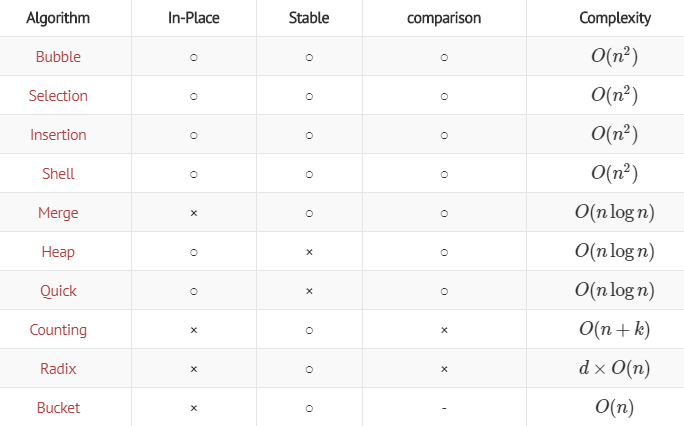
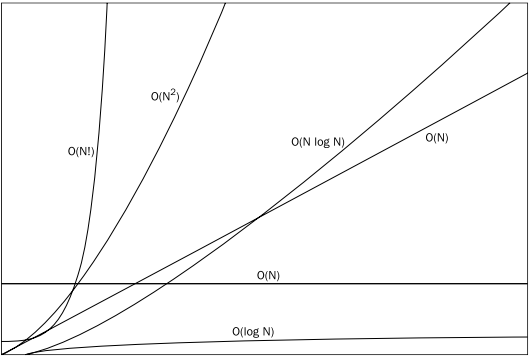
결론
Python에서 얻은 그래프와 위의 Sorting Algorithm별 Time Complexity를 고려하였을 때,
Insertion, Bubble, Selection과 Quick, Merge, Heap과 Radix 가 각각 Time Complexity가 다르며,
주어진 상황에 따라 최적의 Sorting Algorithm은 다를 수 있다.
int main() {
long long Accumulator_ = 0;
std::string _T; // Temporary
std::vector<std::string> pathList_;
std::ifstream openFile_("path.txt"); // Write down all paths of files. Those can be found in properties menu.
std::ofstream resultFile_("result.csv");
_jcode::LineCounter counter_("");
if(openFile_) {
while(std::getline(openFile_, _T))
pathList_.push_back(_T);
}
// 생략
}
